url 주소 입력부터 웹브라우저에 우리가 원하는 웹 화면을 출력받기까지의 과정을 정리해봤다. 사실 거의 번역글이고, 구글링으로 양질의 블로거들이 정리해놓은 글들을 번역하는 과정에서 상당히 배울 점이 많다. 번역을 하기 위해 나도 내용을 알아야 하므로 나도 정리하는 것과 같은 효과를 볼 수 있다.
1. google.com을 타이핑 한다.
2. 브라우저는 해당 url 네임에 해당하는 ip주소를 dns cache에서 먼저 체크한 후, 적합한 ip 주소를 찾는다.
-
참고로 DNS 는 Domain Name System으로. URL name- linked IP address 의 리스트이다.
-
-
DNS 서버가 따로 있어서 해당 url 에 대해, DNS 서버에 접근해서 ip주소를 받은 후, 그 ip로 우리가 정보를 얻고자 하는 웹서버에 엑세스 하는 것임
-
근데, 할 때마다 DNS 서버에 엑세스 하는 것이 아니고, DNS record를 캐싱할 수 있고, 먼저 캐싱되어 있는 DNS record 가 있는지 체크하는 것임
-
참고 DNS Caching Check flow
-
First, 로컬에 있는 웹브라우저 캐시를 체크
-
Second, OS Cache 체크. 시스템 콜로 내 로컬에 깔려있는 OS 단에 접근하여 DNS Record를 가지고온다.(Fetch)
-
Third, Router Cache Check. 드디어 로컬 컴퓨터 바깥의 장비에서 DNS Record 를 체크하는 단계.. DNS Record를 스스로 캐싱하고 있는 라우팅 장비에서 DNS Record Caching을 체크한다.
-
Fourth, ISP Cache check. isp는 자체 dns server를 유지하고 있고, dns record를 캐싱하고 있다. (여기서의 ISP는 인터넷 제공 사업자로, 인터넷에 접속할 수단을 제공하는 주체. Internet service provider)
-
이렇게 DNS record 캐싱을 계층화 하는 이유는 ? -> Regulating network Traffic, improving data transfer times. 를 위함
-
-
- 3. 요청 URL 위에서 언급한 Cache에 없으면, ISP’s DNS 서버가 해당 url(google.com) 에 매핑되는 ip주소를 찾기 위한 DNS Query 를 날리기 시작함.
-
ISP’s DNS 서버가 날리는 DNS Query 는 Multiple DNS 서버들에게 Recursive 방식으로 올바른 ip 주소를 리턴받거나, 찾을 수 없다는 결과를 리턴 받는 것 중 하나를 응답으로 받을 때까지, DNS Server to DNS Server 로 이동하면서 탐색을 합니다.
-
위 내용을 다시 설명하면, ISP’s DNS 서버로 하여금 DNS Recursor를 Call 하는 것입니다. (여기서의 DNS Recursor은 다른 DNS 서버로부터 적합한 ip 주소를 재귀적으로 찾고자 하는 책임을 갖고 있겠죠?) 이제부터 DNS Recursor가 어떻게 작동하는지(즉, DNS 서버에 어떻게 요청을 해서 데이터를 찾아가는지를 아래부터 다룰 것이다.)
-
이때 Domain Name System 서버는 어떻게 DNS Record를 찾냐면, 먼저, DNS Recursor의 요청을 받은 뒤, WebSite 도메인 네임의 도메인 아키텍쳐에 기반하여 DNS Record를 빠르게 Search 합니다. (일종의 Tree 구조로 보여진다.)
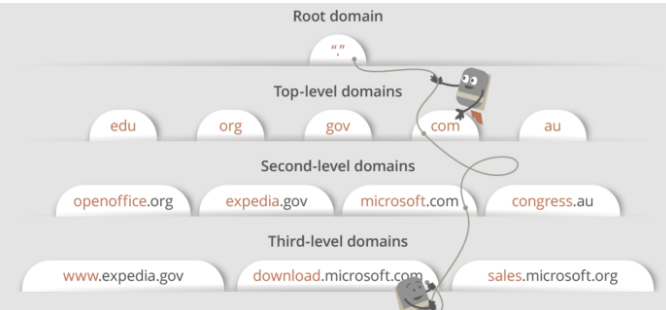
-
DNS 서버의 도메인 네임 검색을 간략히 살펴보면, root -> n th level 의 depth 에 따라 도메인을 순차적으로 찾으며, 일반적으로 url 도메인의 끝자리일수록 상위레벨에서 먼저 탐색을 해갑니다. google.com의 경우, com -> google 순으로 트리 구조를 탐색해 나갑니다. (참고로, 오늘날 웹상의 url 주소는 대부분 third-level-domain 까지 포함하고 있다.)
-
Domain level 계층 별로 다른 서버라고 생각 할 수 있으며, root -> n th level domains 로 순서대로 Redirection 하며, 적합한 ip주소를 찾아나간다.
-
Ex) google.com의 경우, DNS Recursor는 루트 Domain 서버에 컨택할 것이다. 그 다음, “.”root domain server -> “.com” top -level domain server로 Redirect -> “google.com” second level domain server로 redirect -> 여기서 매핑되는 적합한 ip주소를 찾는다.
-
DNS Recursor로 하여금, DNS 서버들에 보내는 Request들은 스몰 데이터 패킷으로 되어있고, 1. 리퀘스트의 내용, 2. DNS Recursor 주소를 가리키는 ip주소 등으로 이뤄져 있다. 이 요청은 적합한 DNS 서버 장비를 찾기 전까지 클라이언트와 서버 사이의 네트워크 장비를 패킷 형태로 오가며, Traveling 한다. 네트워크 장비는 라우팅 테이블이며, 라우팅 테이블은 이러한 패킷의 목적지까지 도달하는데 가장 빠른 길을 맵핑시켜준다. 이 단계에서 패킷 손실이 일어나면, Requested Fail Error가 뜨는거고, 적합한 DNS 서버를 찾으면, 맵핑되는 ip주소를 얻어서 클라이언트의 브라우저로 다시 돌아온다.
-
- 4. 브라우저는 서버와 TCP 커넥션을 시작한다.
-
-
브라우저가 한 번, 적합한 ip주소를 비로소 받게 되면, 해당 ip 주소와 맵핑되는 서버와 TCP Connection 을 Initiate 한다. (정보 전송을 위함) 인터넷 프로토콜에는 여러 프로토콜 타입들이 있지만, TCP 프로토콜은 많은 종류의 Http 요청에 사용되는 보편적인 프로토콜이다.
-
TCP 프로토콜위의 TCP Connection의 원리는 TCP/IP Three way handshake 이다. 이 3단계 프로세스는 서버와 클라이언트 간의 SYN(싱크), ACK(알아차림) 메세지를 교환하므로서 TCP 커넥션을 맺게 해주는 것이다.
-
3 way handshake 프로세스를 좀 더 자세히 설명하면,
-
1. 먼저 클라에서 인터넷 위에서 서버에 new connection을 요청하는 SYN packet을 보낸다.
-
2. 서버가 이 요청에 대해 통신을 하기 위한 포트를 열고, new connection을 개시한다면, SYN/ACK 패킷을 사용하여, 해당 SYN 패킷에 ACK 패킷을 붙여서(?) 응답한다.
-
3. 클라이언트가 서버로부터 SYN/ACK 패킷을 받아서 다시 서버에 ACK 패킷을 날려준다.
-
그럼 1,2,3 단계에 따라 서버와 클라 간의 TCP Connection이 만들어진다.(이제 Data Transmission 이 가능..!)
-
-
-
-
5. TCP Connection이 된 이후, 브라우저가 웹서버로 http request를 보낸다.
-
목적에 따라 여러 방식의 http method를 사용하여 request를 보낸다. (폼 제출이나, credential 에 진입 할 때는 post, google.com같은 경우에는 get. )
-
이때 http request 의 헤더에는 여러 종류로 이뤄져 있고, 이들을 포함할 것이다.
-
브라우저 식별 정보를 담고 있는 헤더(Browser identification info/ a.k.a user ‘User-Agent Header’),
-
accept header
-
그리고, connection header는 추가 요청에 대해 tcp connection을 유지해달라고 요청하는 정보를 담고 있음
-
또한 request 에는 브라우저가 해당 도메인을 위해 저장하고 있는 쿠키 정보도 담아서 보낸다.
-
-
위의 내용을 종합하면 http request 의 심플 버젼은 아래와 같은 정보를 담아서 보낸다.
-
-
브라우저로부터 받은 리퀘스트를 서버가 Handling 해서 Response back 해준다.
-
서버는 웹서버를 포함하고 있고, 이 웹서버가 브라우저로부터의 요청을 Request Handler로 전달해준다. Request Handler는 요청을 전달받아서 읽고, 연산하여 Response를 생성한다. Request Handler는 일종의 프로그램이고, 여기서 우리가 코드로 쓰는 백엔드 프레임워크가 사용되는 것이다. Response는 특정한 포맷으로 재조립되서 보내질 것이다(JSON, XML, HTML 등)
-
-
서버가 http response를 보낸다.
-
http 서버 리스폰스 메세지는 status code, compression-type(content-encoding), page를 어떻게 Cache하고 있는지, 프라이버시 정보, set해야할 쿠키 정보 등을 담고 있다.
-
아래가 http response message 샘플임

-
-
마침내 브라우저(클라이언트 단)가 HTML Content를 출력한다.(For HTML Response, and it’s the most common case.)
-
먼저, Bare Bone 형태의 html 골격을 랜더링한다.
-
이후, html tag를 체크하고, 웹페이지상에 추가로 필요한 element(css stylesheet, image, js file etc..)가 있을 때 get request를 서버로 보낸다.
-
1. google.com을 타이핑 한다.
2. 브
1. google.com을 타이핑 한다.
2. 브
1. google.com을 타이핑 한다.
2. 브



